
Navigating politics can often feel like a revolving door of complaints and leadership changes. But let’s pause for a moment. Can every leader truly be all that bad? (A few corruption cases aside), it’s most likely they were doing their best. Ironically, we find ourselves mirroring these dynamics in our gripes about data projects within businesses. If you buy into the idea that “the fish rots at the head,” we’re not so different from federal politics. Does this sound familiar – “our data is a spaghetti mess, held together with gum and sticky tape”. Business leaders, too, are doing their best, grappling with issues in data projects that are innately challenging. Let’s cut ourselves and leaders some slack, focus on incremental improvements, and direct our attention to what truly matters at the heart of every data project – data engineering. Leading ourselves to a more peaceful world…
Business plan
Crafting a robust business plan is the cornerstone of effective data engineering. Without it, your data systems lack a foundation to stand on. It’s about defining your business’ long and short-term goals, understanding the phase it’s in—especially crucial during growth phases—and outlining strategies for growing: revenue, customers or users. Equally important is defining metrics to measure the plan’s effectiveness and course correct when necessary. But here’s a crucial checkpoint – how well is your business plan communicated across your team? The success of your data endeavours hinge on every member understanding and aligning with the plan. Otherwise, it’d be like an app developer building a new feature and not knowing what the app is. To do the best data engineering, you need to know how data is going to be used, and the starting point for this is a business plan.
Data strategy
You’ve got a solid business plan so now you’re ready to craft your data strategy; “How will your data help you drive your business plan?” Here are the types of questions you will need to ask:
- What do you need more, predictions or insights (or both)?
- What is the priority for delivering the above? (We can’t “boil the ocean”, it’s the focus that delivers value)
- How can your data be used to both operate and optimise your business? (Noting the for the later, exactitude requirements are traded off for more data. Whereas operational data stores necessarily require high exactitude for regulatory or revenue preservation reasons.)
- What data do you currently store, what data do you need to start storing?
- What data within the business do you have and what do you need to seek?
- How reliable are the datasets you have, what analysis is needed to understand this better?
- What is the signal in the noise? (Of all your data sources, which sets and subsets thereof will yield the most reliable predictions and deepest insights?)
These types of questions will enable you to have an understanding of the data you will use and what you will need to do with it to optimise your business (value and veracity). Then it’s time to dig deeper on the technical aspects…the volume, velocity and variety of your data and build out your data architecture…
Data architecture
Data architecture is merely a data engineering plan, it’s not its own discipline. Another way to think of it is: that it’s nothing more than a software architecture with data flows included. Data engineering is a type of software engineering so we need to maintain the same principles of software architecture, which is focussed around the question; “What do we want to know and document (diagrammatically) at the start of the project in advance?” For this we need to ask:
- What are the main software components we need to use and why?
- Can we decide these later or should they be decided now?
- What are the constraints for components we can use? (e.g. what components do we have in operation already, what are our current skillsets – e.g. SQL, Python, Kubernetes, Google Cloud etc)
- How will our data flow between these components?
- What data storage systems will be used to operate our business compared with optimising our business?
- What systems will be used across both of the above?
- How can we test our components?
- How can we deliver these components iteratively with an adaptive plan?
- And most crucially to yield an enduring benefit – how can we maintain the solution?
Now more specifically for the best data engineering:
- How much data do we have and how fast is it growing?
- How many different types of data do we have over which different storage systems?
- What storage systems will we need for processed & transformed data: OLAP, OLTP, NoSQL etc
- Who is mastering and managing these data sources (internally or externally)?
- How could we clean our data for the best reliability?
- How could we unify our data sets to a 1 or very few unified data models?
- How could we automate our solutions?

Building the solution – data engineering
You’ve got your business plan, your data strategy and data architecture – let’s call this the “hierarchy of knowledge”, now the real fun begins! You’ve got to build the solution; at its core this is a sub-discipline of software engineering. It’s writing code and connecting systems (to process and automate dataflows). Counterintuitively though, a significant part of this work is not actually coding and building, it’s thinking. There’s often dozens of ways to solve a problem and so before we work hard on a solution, we want to work smart at knowing how best to solve it. The same philosophies of agile software development apply in that you want to develop incrementally in “thin slices” with a plan that is adaptive. But to add to this, you’re not just doing regular software engineering (where people use the term web developer interchangeably) to build features for end-users, your features are directly in service of optimising a business. And so the thinking aspect of data engineering forces you to look across the hierarchy of knowledge, before and during your coding work because you need to remain focused by considering:
- What is our data architecture and how might this new feature sit within it?
- If #1 is still unclear, what is our data strategy and how might we adapt our data architecture to fit this.
- If #2 is still unclear, what is our business plan and how might we adapt our data strategy to fit this.
Once you begin thinking through the above for clarity in your proposed solution, often you need to analyse your data to know if the solution is meeting the hierarchy of knowledge sought. For example if your strategy is to grow revenue by predicting and recommending products based on user behaviour, you need to analyse your user data to know what can be predicted. If your user behaviour data is a swath of independent attributes perfectly cleaned and curated then you’re well on your way. However, if you have no site tracking data, no knowledge of customers on your site other than anonymous user behaviour, then you have some more work to do.
Coding maintainable solutions
So now you’re clear on your hierarchy of knowledge (above) and have thought through how to work smart on the solution, you need to write code. It takes a skilled professional to write the best code, which is often highly technical and analytical work, however at its core it’s communication. Good code is a love letter to the next engineer who will maintain it. It’s easy for a competent engineer to write code for themselves to maintain, but it takes a great engineer to write code for someone else to maintain. Let’s not confuse an engineer’s value with how much we need this person to maintain the code. If their code is not written such that another good engineer can maintain it, then the code’s value is limited. Fortunately there are a set of principles we can adopt in order to create the most maintainable solutions across all engineers:
- Name things as accurately as possible
- Does the function/module/package do exactly the thing its name says it does?
- Is the variable/class/interface – exactly the thing it’s name says it is?
- Separation of concerns – is the thing you’ve named doing just one thing or many?
- If its name is like a long sentence then it’s probably doing too much, turn it into two or more things instead!
- Don’t Repeat Yourself (DRY) – don’t copy your code, use the same code over and over!
- If two things are 80% the same functionality with two separate blocks of code, perhaps make that 80% it’s own thing and call it twice from each block.
- Do you need the thing in the first place? – Ruthlessly consider what code you actually need, brevity is your friend (see yagni)
- The human mind can only typically absorb 7 things so keep things brief! As a rule of thumb, try to keep to 7 or less of each of these:
- Lines per function (this one could perhaps be stretched slightly further with logging/alerting/comments)
- Functions per module/class/file
- Modules per package/folder
- Folders per parent folder
- Write testable code – if you can’t test your code, then it’s likely one of the first five above has failed, so perhaps think about this one as your guiding principle.
- Write tests – testing is an investment
- A prerequisite of good testing is writing testable code in the first place. So don’t just test what is testable. Make all of your code testable.
- You won’t see the benefit of your tests straight away but that’s the nature of investing. You’re investing time now to gain considerable time in the future.
- Focus on testing the most critical aspects first. You can’t test everything straight away always so prioritise your tests.
- CICD
- Can your code be integrated into your solution seamlessly and automatically?
- Are all the deployment steps to each environment automated (testing, building, moving code, moving configs, validation etc)?
- Use maintainable infrastructure – code needs to run from somewhere that is reliable.
- Choose infrastructure you understand and can manage
- Look at your metrics, how well are your servers/containing performing
- Are logs and alerts helping you catch major issues before they arise
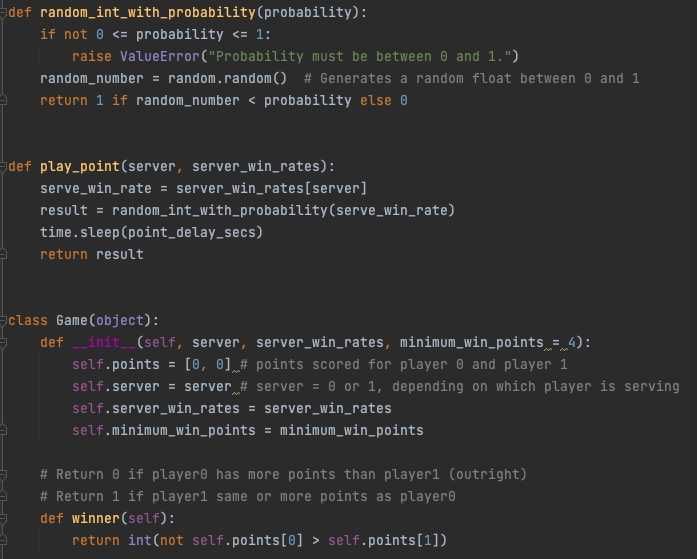
(^ can you guess what this is?)
Modelling – the final stage
If you have your data engineering running smoothly, your business will see immediate benefit because data can be used to report on what is working well and what isn’t. People can make more informed decisions than their otherwise lack of access to: clean, reliable and updated data would enable. This already gets you huge benefits alone.
But you want to go one step further; predict the future and look deep within your datasets for the richest insights. You want to create models on your data. Whether this is: a machine learning prediction model, a simulation, bayesian/frequentist statistics or a domain specific calculation, it’s driven by solid data engineering. In some ways this last step, although more heavily linked to mathematics and statistics, is actually just yet another sub-discipline within data engineering itself. All the rage has gone in recent years towards AI and Machine Learning for obvious reasons but the unsung hero which should not be forgotten is “deterministic processes” (e.g. business rules). There’s two crucial data engineering processes that need to be built in tandem:
- Non-deterministic processes: you don’t know the expected outcome before running it
- Machine learning
- Other forecasting models
- Simulations
- Deterministic processes: you know the expected outcome before running it
- Business rules and processes
- Financial calculations
- Application functions
Ideally you need both to be working in harmony. For example, before you go ahead and tune your prediction models further with a fancy new algorithm, consider how your business rules can help with advancing your data strategy since model optimisations can have diminishing returns beyond a certain point (it’s hard, the world loves to make predictions but we’re not very good at it). Also, models are experiments whereas business rules are known features with more well defined value to attain. It’s possible to get more hard-hitting value with predictions but it needs to be balanced with regular deterministic processes. Finally, to make sure you’re moving the needle, measure the effectiveness of your models, including factors such as:
- The business metric you’re optimising: e.g. revenue per customer
- The model metric to enable the business metric e.g. F1 score of an ML model
- The tradeoff between bias and variance
- The tradeoff between precision and recall

Peace
So what’s all this for? We’ve used our data to optimise our business. Now it’s earning more revenue than it was a year ago and shareholders are happy. So what. Your business is a product of capitalism, which is the world learning how to do things a little bit better each time. Typically, that’s what you’ve done if you’ve grown revenues; you’ve delivered value to your customers in some way, either by offering: new & unique, cheaper or more convenient products & services. Lets not underestimate that there is considerable learning taking place to achieve this. It’s learning about your business, but this can’t be isolated because it’s also learning how the world works. The more we learn about the world, the more we can make the lives of those around us better and more peaceful. Learning happens through data. As a business, this starts with your data.


")