Film Fan is your very own personalised film recommendation engine. Please check it out here: filmfan.ai. A full walkthrough of the site’s features and inspiration is covered in a previous post: here. In this 5 part series, I will break down how I designed and built Film Fan, taking into consideration my requirements and goals below. There’s many film recommendation engines, however Film Fan has focussed first and foremost on data. Collecting data to feed machine learning models is at the heart of this engine, precisely because each model is personalised to each user.
Goals
Starting out as a passion project, Film Fan grew into something a little more. As an avid film fan myself, to begin with I just wanted an easy way to find films that would have a ‘life-altering’ impact on me. Broad in nature, some examples include: “I Am Sam”, “Schindler’s List”, “Beautiful Boy” and “Black Swan”. I knew that to find these types of films, I’d need to cast a wide net, i.e. all 10k+ films (instead of 100s of films on offer from a single streaming service). I needed to search all English-native films (ever made), using AI. Various other solutions have been around for a while, however I knew that to reach new frontiers, I would have to put myself at the centre of this problem and start collecting my own data to feed the AI; to collect data in the best and simplest way I know how. To that end, Film Film at its core is a data collection machine, with AI recommendations as an output. This begs the question, and the direction for this project: “How much data would one need to collect in order to find their life-altering films”?
Requirements
Although I have many friends providing advice on: data, ML and technology, it was just me building Film Fan, with no sizable budget; just some spare money I had for cloud services and my own after-hours time. Hence the overall solution needed to be: low cost and easy to maintain; I would need to be ruthless here and trade this off against more features and aesthetics. Additionally, although I’m a seasoned data expert, I’m not a seasoned web developer so the web requirements would need to be lightweight. I’m fairly happy with how the web components have turned out, but this can be enhanced. As mentioned, Film Fan is a data collection machine, so this component was designed and built first, and then everything else around it. So to summarise and break this down, it required:
- Low cost – no more than $50 per month in cloud services.
- Services that “scale to zero” – i.e. cost nothing if you don’t ‘use’ it, or very little if you use very little.
- Following on from (a), services which separate storage from compute.
- Can scale as usage of these services increases without effort.
- Simple to maintain
- Simple, maintainable code (which I talk about here).
- Separation of distinct modular components, especially for back-end data processing jobs.
- Out of the box support for dev tooling: logging, altering, code builds etc.
- Data collection focussed
- Fast and low latency collection of film review data (client side) for the user.
- High concurrency read/write of data.
- Low latency access for individual records.
Data Collection
To collect as much data as possible, quickly and with low effort, the user data collection needed to be a seamless process; merely 1 click per film review (i.e. data collection point). For both desktop and mobile, for each film review, it required:
- No scrolling
- No popups
- No multiple clicks
- The same data in the same intuitive place for all records
- No resizing
- Single page application
- Client side processing (for lowest possible latency).
Here’s what it looks like:
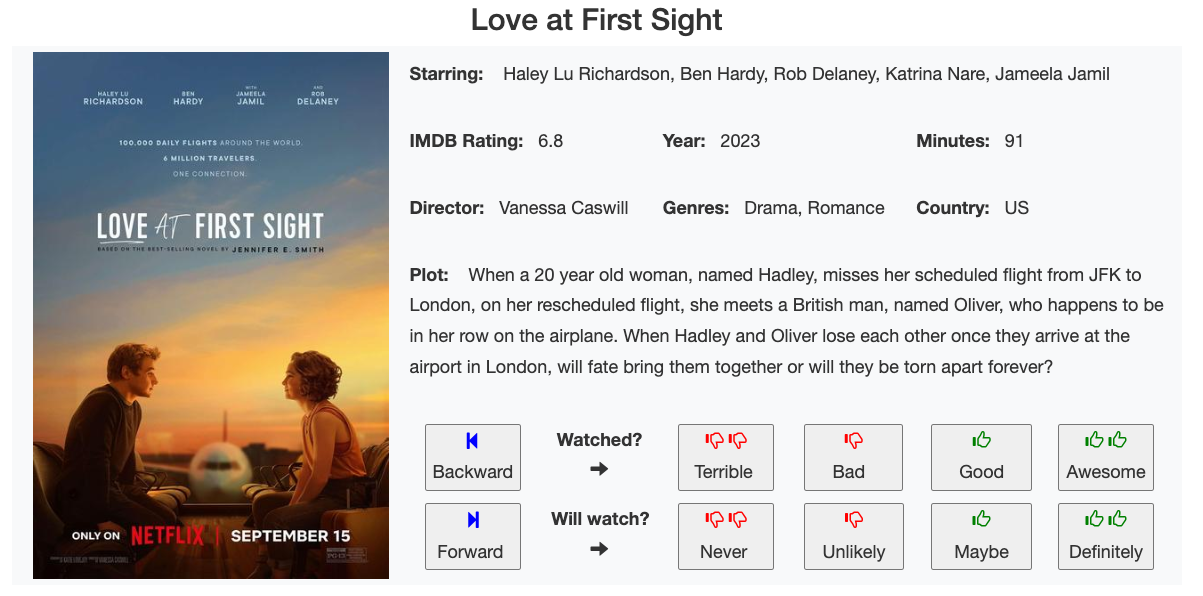
You have all the main information you need to know if you’ve watched it
and if you haven’t then you quickly gloss over the details and covert-art to give it a score.
The scoring methodology also needed to be simple. In an ideal world you might give each film a score out of 100 and carefully compare one against the other. But time is of the essence when you’re reviewing 100s/1000s of films. On the other extreme you could more easily just say “thumbs up” or “thumbs down” but that doesn’t always work because there are some films you know in your heart are just on another level to all others that were just “good”. So then, a score out of 4 seems like the right amount. Since it’s an even number it means there are no fence-sitters, you either liked it or you didn’t, and either extreme of that. Similarly for how you judge the film having not yet watched it.
The review page runs as the entry point to the website (after login), and the next films are loaded client side from Google’s Firebase database, after each button press (a film review, or back/forward being pressed). Cover art is served from Google Cloud storage pre-cached in advance. Vue.js is the javascript library which updates the elements and calls Firebase to read film data and store film reviews. Data points for film reviews are collected in 3 different firebase collections as elaborated upon in a later part of this series (current reviews, historical reviews, reviews since last cache).
Cloud components
I’ve used all of the mainstream cloud providers and also many 2nd tier SAAS/PAAS cloud services over the years, Google Cloud I’ve found is the best to work with for data projects. (NB: I have no affiliation with Google). This makes a lot of sense, since Google itself is a powerhouse of data & AI internally and so commercial versions of their rock solid internal tools often become Google Cloud services for the public. Additionally, they always seem to have an option to ‘scale to zero’, in other providers you often need to leave at least 1 or more services running (and paying for it) when you’re not using it. Data projects are inherently ‘bursty’ in nature which is why this is so important from a cost savings perspective. Unless you’re a big commercial company running services for profit, there’s really no better way than to use only services that scale from zero to infinity (without much effort). The main cloud components used are:
- Big Query – analytics engine (transformations and ML)
- Firebase – data collection and serving film details to web site
- Cloud run & cloud scheduler – data and ML processing jobs
- Google App Engine – containerised scalable web server (PAAS)
- Google Cloud Storage – file storage for data caching and package management
- Cloud Build, Stack Driver various service dashboards – out of the box dev tooling for building code, logging and alerting
There are other services available to yield an even faster and more polished solution, however they are far more costly and hence these trade-offs had to be made. I’ll speak more about these in future posts.
System Architecture
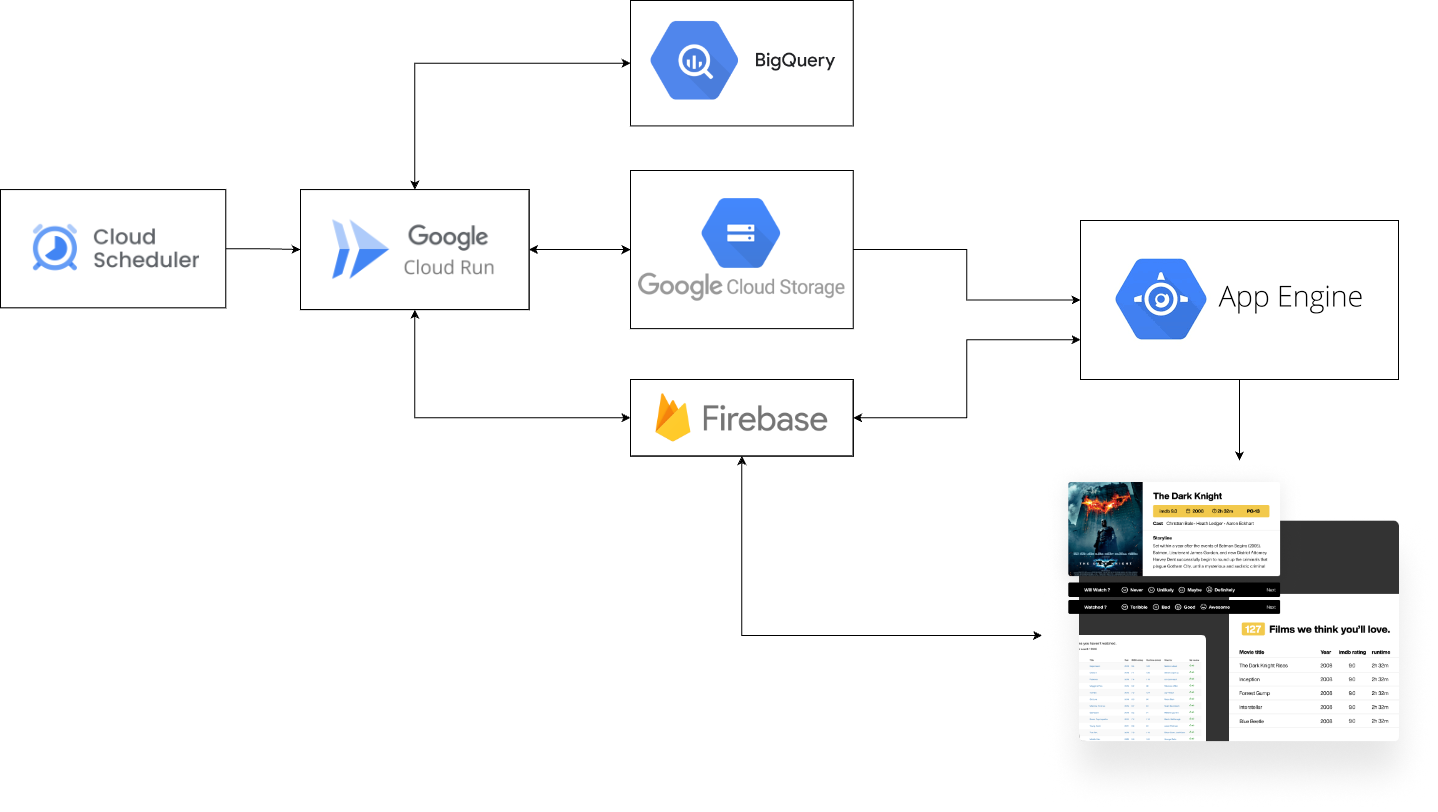
As described above, each cloud component is chosen to perform a specific role in the system. Here are the main points referring to the above:
- Each cloud run job is triggered on a separate schedule by Cloud Scheduler
- Cloud run jobs can read and write to all data storage systems: BigQuery, Firebase, Google Cloud Storage (GCS).
- App Engine serves web pages and reads data only from Firebase and GCS.
- The client side of Film Fan (without App Engine) also interacts directly with Firebase
- Storing film review data (data collection)
- Reading film details data (to load new film page)
Code repositories, jobs and packages
The code is structured into various repositories which represent either: a data/ML processing job, application or utility library (as python package). Here is a summary of all code repositories:
| Repository | Type | Schedule | Role |
| Film cache | Cloud Run Job | Daily | Get film data from Cinemagoer API (formally ImdbPy). |
| Process film data | Cloud Run Job | Daily | Process all film data (including determining which films to cache). |
| Users and recommendations | Cloud Run Job | Every 30 mins | Save user reviews to BigQuery and run ML training. |
| Web app (front and back end) | App Engine | N/A | Flask app for Film Fan app, including Vue.js client side code. |
| Google cloud library | Python package | N/A | Generic functions for using Google Cloud (e.g reading/writing to storage systems) |
| Film Fan library | Python package | N/A | Film Fan specific functions (e.g. for processing data so that front and back end transformations are consistent) |
These code repositories will be further broken down in subsequent posts. In particular “Process film data” which performs the bulk of the data engineering transformations, including ML pre-processing and automatically ingesting new data.
Data & ML pipeline diagram
See below a simplified view of the core data engineering and ML engineering flows across the two core storage systems: Firebase and BigQuery. The intention of this diagram is to show how data is transformed from the point of view of creating the required output tables for:
- Ingesting new film data.
- Ingesting new user data.
- Transforming the above for machine learning and analytics.
- Transforming the above to serve within the Film Fan app.
For this reason, the data flows to/from GCS are not included here since they’re replicas of all/part of the below tables for app caching purposes (i.e. improving speed in app).
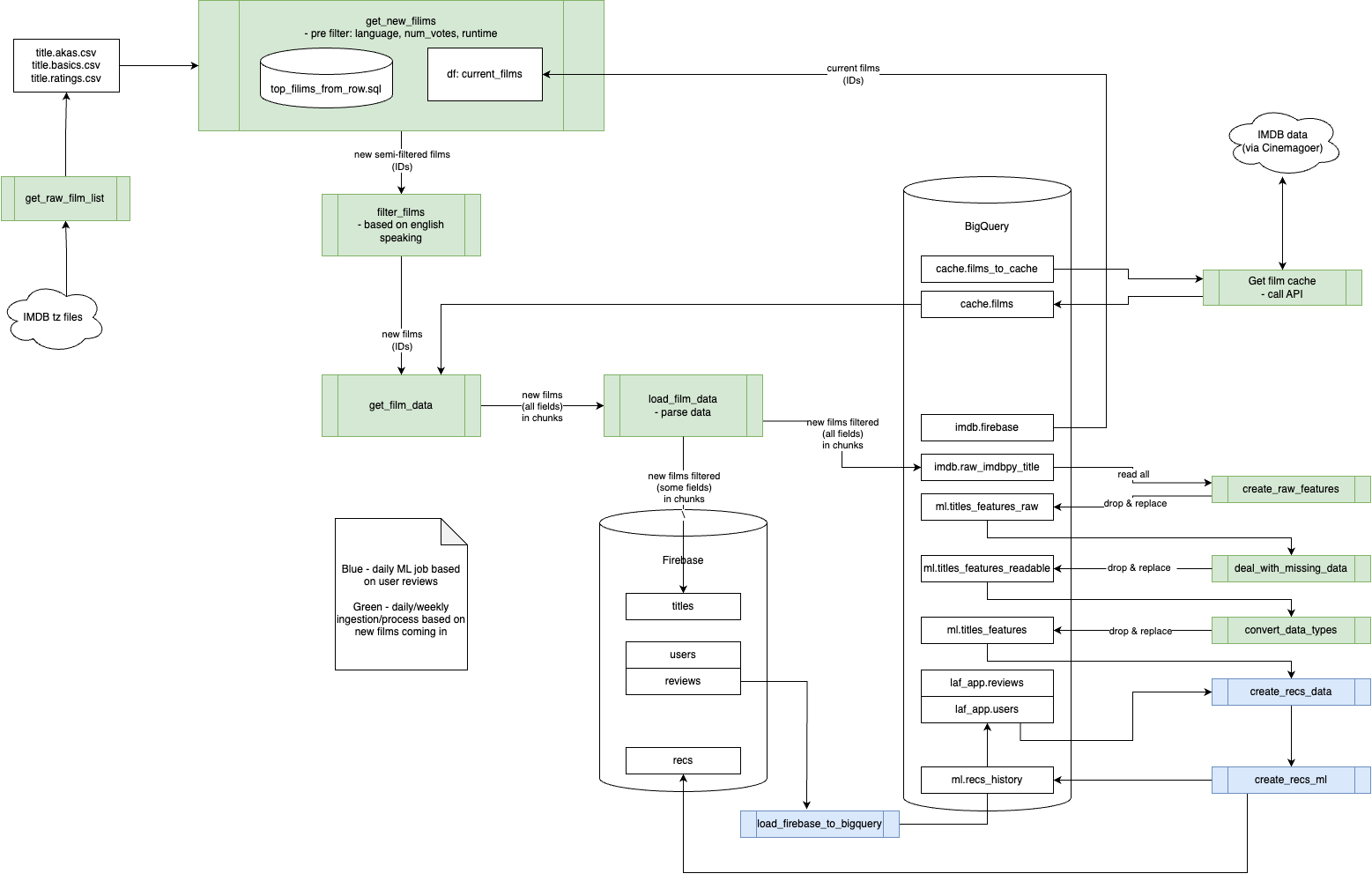
Here are the main points referring to the diagram above:
- Green boxes relate to ingesting and transforming new film data. This also includes ML pre-processing because ML features are based on film content which can be performed on film ingestion.
- Blue boxes relate to ingesting new user reviews and running ML training for each user. This schedule necessarily can be performed independently of ingestion (at present every 30 mins)
- Data stored in Firebase is often replicated in BigQuery within these processes since BigQuery is optimising for processing data whereas Firebase is optimised for collecting data.
- With more resources and budget, we could ideally setup a Kafka to stream this data directly to both storage systems
- Wherever possible, data is processed by way of ingesting new records. A few exceptions to this exist where a drop and replace pattern is needed:
- New films are only known through csv files provided by IMDB – this entire film database is several GB which have updates most days.
- ML pre-processing requires data sources to create features which are updated periodically. For example: currency and inflation rates or new film attributes like director/actor/producer etc.
Major challenges
Film Fan, like any complex software project, encountered several challenges. Fortunately after years of experience processing data, I was able to plan for and mitigate most data issues (which I’ll explain about later) even if they did require some time given the scope of work. Here are a few main challenges which stand out:
- Creating a web app with heavy client side data collection functionality (without a lot of web experience)
- Making the site performant enough to be usable
- Sourcing the film data
- Breaking down the data processing code into logical modular pieces of work
- Setting up cloud infrastructure to be cost effective while maintaining performance and usability


")