Epilogue: Film Fan is your very own personalised film recommendation engine. Please check it out here: filmfan.ai. A full walkthrough of the site’s features and inspiration is covered in a previous post: here. This is a 5 part series to break down how I designed and built Film Fan, from all angles: data, engineering, analysis, machine learning, speed, productionisation, cost etc. For reference, please also see the previous post in this series: Film Fan – Under the hood – Overview.
This post is all about the data (and engineering thereof). I use the term “data engineering” broadly to encompass: the reading, writing & processing of data, which also includes machine learning and the creation of production grade automation systems for on-going reliability.
Data sources
Let’s first focus on the data sources we need and work backwards from there. As mentioned in a previous posts, Film Fan is a content based recommendation system, meaning the features (i.e. data columns) required for prediction are all sourced from the film details (and not other things e.g. similar users or app based event data used by streaming services). To that end, the data sources can be broken down by the following:
- User data
- Who is the user (based on login)
- How did the user review (i.e. score) the films
- Film data – the list of ~18k films and their attributes:
- Name
- Plot
- IMDB rating
- IMDB number of votes
- Year
- Runtime
- Film colour
- Genres
- Country
- Languages
- Cast
- Directors
- Writers
- All other relevant parties e.g. Producers/Distributer/Special-Effects/Cinematographers etc
- Budget
- Revenue
By being focussed on film data, we can build models that predict user preferences (i.e. recommendations) based on film attributes that are well known to be linked to said preferences, in particular:
- High scoring films that are heavily reviewed, e.g. if no one has heard of the film, let alone reviewed it well, then it’s unlikely to be valuable.
- Newer films in colour, e.g. a 8.1/10 review in 1920 might not be as valuable compared to the same in 2020 (or maybe more if the user was older).
- Films with celebrated actors/directors/writers etc, e.g. Tom Hanks, Martin Scorsese etc could be more valuable.
- Budget and revenue – to determine the size and scope of the film as a project, e.g. with bigger budgets perhaps you can attract better cast and crew. Or perhaps some may prefer indie films with smaller budgets.
Transformations – Film data
The source data described below have been transformed into a variety of formats in different SQL/NoSQL storage systems depending on the use of this data.
Source data
- Flat daily CSV files from IMDB – used to find the entire film universe.
- Cinemagoer API (formally known as IMDBPy) – used to receive all raw film attributes in JSON.
App
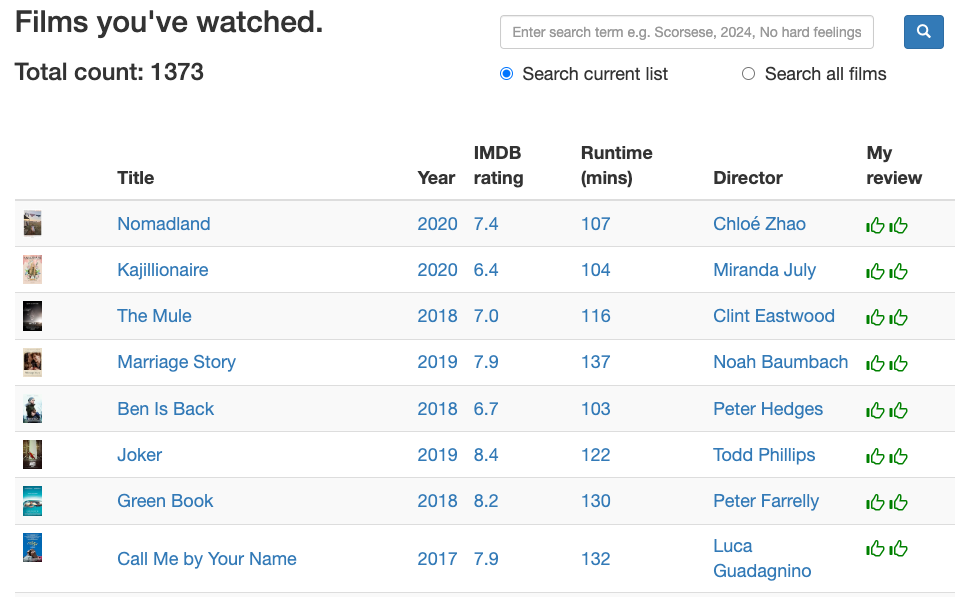
A subset of the fields listed above are stored in Firebase, with each film as a new document within a firebase collection. When the user reviews a film or clicks back/forward, a new film document record is loaded (with their previous review score highlighted where applicable). See example of film data below:
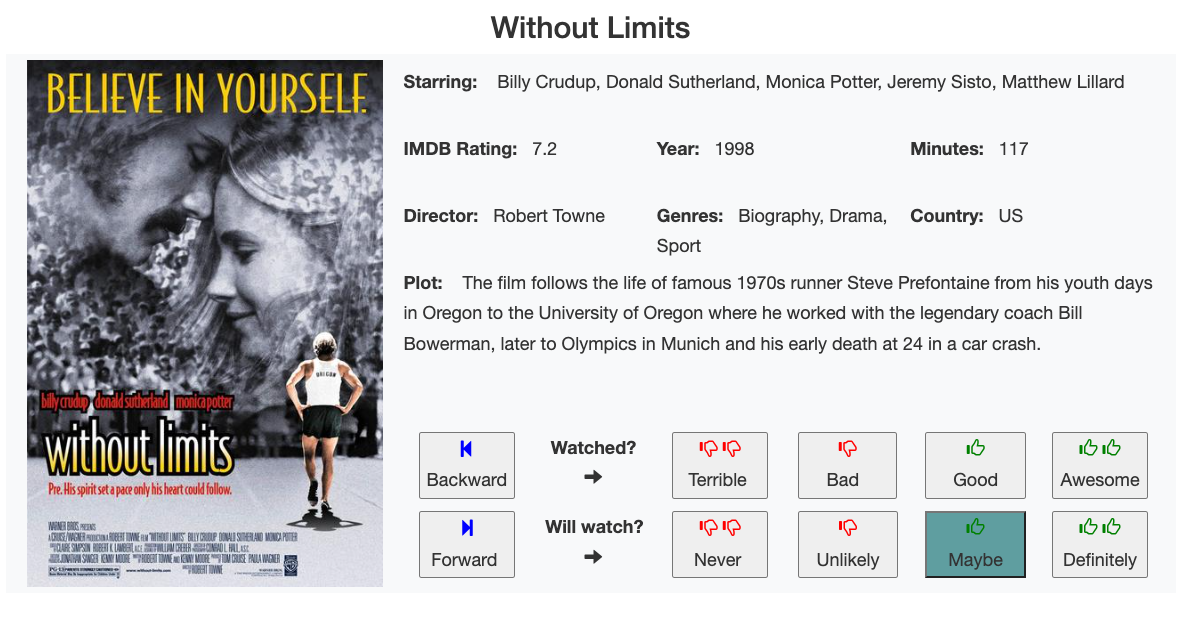
Additionally the entire film database is also stored in-memory within a pandas dataframe on the web-server (Flask on Google App Engine). This is used for knowing the order to serve films for review purposes, as well as speed in: presenting film lists and search engine. The pickled data frame is read from Google Cloud Storage when the Flask app starts up.
Analytics and other transformations
The entire film database and daily ingestions thereof (which feed the app) are initially stored in Big Query. This is the source of truth for Film Fan’s film universe (from which the app data above is derived).
There are a variety of different film tables for a range of purposes outside of simply displaying films to review, including intermediate processing steps and the machine learning process (see diagram overview page here).
The film table structures (and hence transformations) depend on the use case within the system, however to give you an example see here film data from Cinemagoer API:
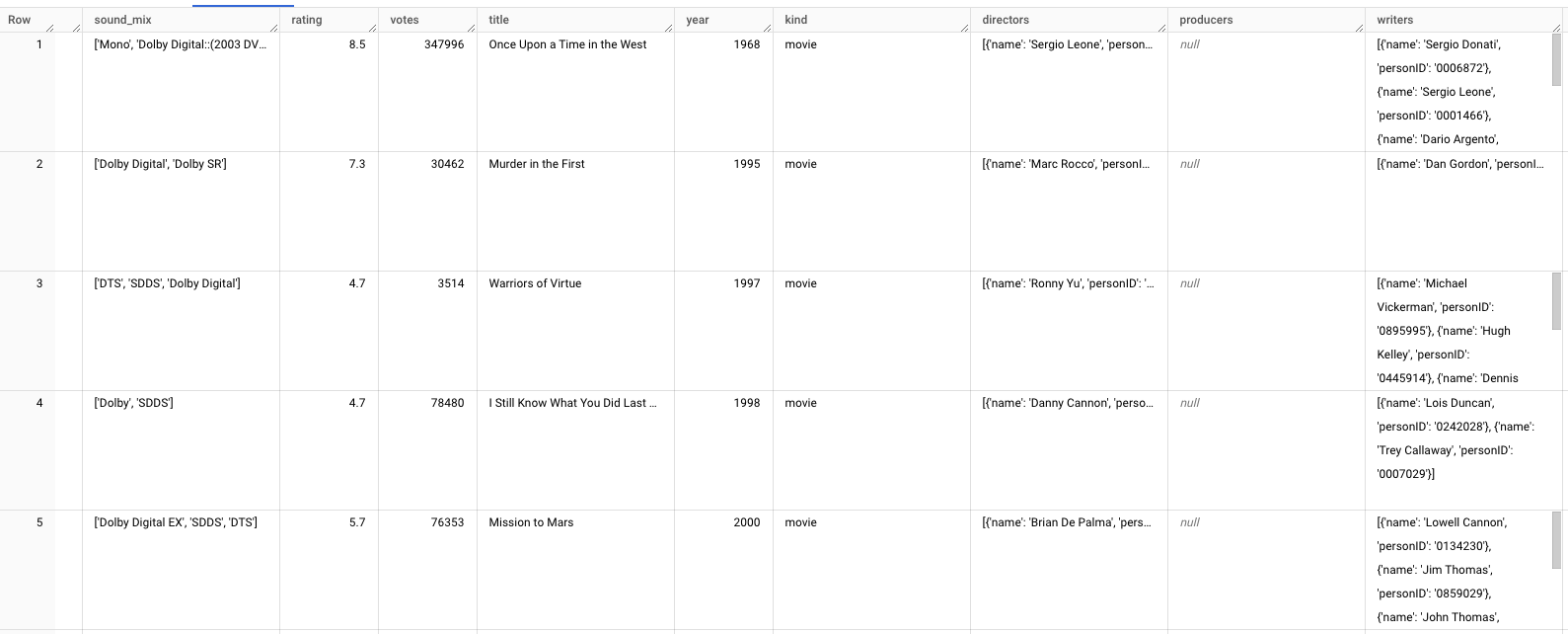
…compared with final table for training machine learning models:
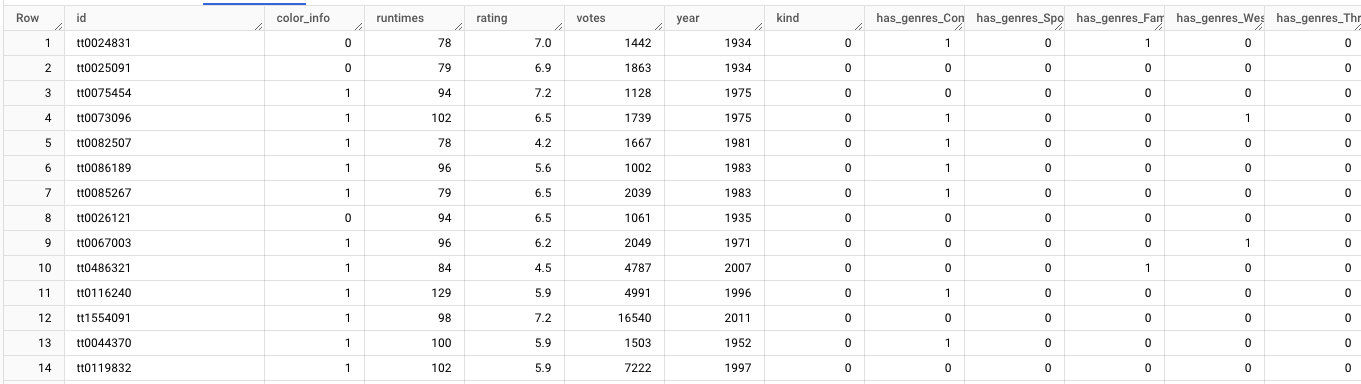
Transformations – User data
The transformations of user data from an analytical point of view are much simpler because the core data records are merely:
- User ID
- Film ID
- Review score (have/haven’t watched and rating thereof)
- Timestamp
The the challenges for user data are more systematic in nature and broken down into 3 areas:
- Transfer data from Firebase to Big Query (since all user data is captured by Firebase)
- Although Firebase works well for low-latency and high-concurrency reads and writes, it has a very limited query engine hence for analysis and machine learning preprocessing we need an analytics query engine (i.e. Big Query)
- Maintain model reproducibility so that we know for every user, which data and model parameters were used to train their ML model at any particular time. (For this we need historical data.)
- Speed – since we don’t want to be reading many user records from Firebase often (see “Speed” section below)
As such the film review data for each user is stored (and hence duplicated) in 3 Firebase collections
- Reviews – the source of truth for all reviews as of now.
- Historical reviews – all reviews ever created.
- Current reviews – the reviews since the last caching (see below).
Speed
When processing data on either the front or back ends, speed is off the essence. Here’s how Film Fan handles the front-end (including app caching techniques).
Front end
Front end processing is typically more important since if the user needs to wait too long for a page to load, the experience is compromised and there is risk they abandon the app. Typically a few seconds is tolerable, but 10 seconds or more is unacceptable. Here are the main front end processing actions for which speed is crucial:
- Logging into app and loading “films to review”
- Loading a film list: watched, unwatched, recommended films.
- Loading a new film to review (after clicking the review button).
#1 and #2, follow the same pattern since they are just different sets of film lists (#1 is unreviewed films). If the app were to read all watched and unwatched films from Firebase for the user each time, this would often take much longer than 10 seconds (Firebase is designed for single reads/writes; not bulk nor analytical query reads/writes). To get around this we make use of Google Cloud Storage (GCS) as part of the overall app caching.
#3 is simple because it’s built into Firebase. The only optimisation is to cache the film cover art ahead of time, instead of pointing to its source link (which may be far from the app).
App caching
There are two main types of app caching to load data as fast as possible:
- Flask caching
- General app data (e.g. film universe)
- User app data (e.g. list of “watched” films)
- User caching through GCS
#1 is merely the app caching feature built into Flask for speed purposes that keeps variables on the web-server in-memory that are retrieved often. This is quite useful in general, however there is no guarantee that this data stays in memory since web-servers can be restarted or new instances are spawned from from Google App Engine. Plus after a period of time (hours) the cache is cleared from the web-server.
To overcome the limitations of #1, #2 is also used such that if cache #1 is empty (or invalidated) then the app seeks to find a list of films (e.g. “watched” films) by combining two data sources:
- The list of films in this film list for this user (as per the last “Users and recommendations” job), as a pickled dataframe in GCS.
- The list of films that have been added to “Current reviews” Firebase collection since #1 has been completed. (i.e. based on new user reviews in current session)
By combining these two, we can guarantee we have all films up-to-date for this list for the user. And since #1 typically forms the bulk of the film list and loads very quickly (fraction of second), most of the time film lists can load within a few seconds (which would otherwise take up to 10s of seconds with Firebase alone).
Data and ML engineering
As mentioned in Film Fan overview, there are several data & ML processing jobs and utility libraries (as python packages) to achieve the above processes. The ML engineering will be discussed in a later post, however to give an idea of some of the complexity within the core data engineering job, see breakdown of the steps involved for the “Process film data”:
Process film data
Please refer to diagram “Data & ML Pipeline” in Film Fan overview:
- Get raw content CSVs from IMDB (100s of thousands of records ~10GB)
- Store the above in SQLite database
- Retrieve by way of query all films which meet minimum criteria of rating/votes/English-speaking/is-a-movie (i.e. a film worth considering for Film Fan’s universe)
- Retrieve from film cache table, which comes from Cinemagoer (not to be confused from app cache) all films originating from an English speaking country
- See if any new films exist (not yet ingested) by comparing to existing table
- If there are new films:
- Parse film data (to convert JSON to format for tables in Big Query)
- Load film data to Big Query and Firebase
- Download covert-art to GCS
- If there are new films, run ML pre-processing pipeline:
- Create raw ML features from films database by standardising columns
- Convert budget and revenue to standardised values (present day estimates in USD) by applying:
- USD inflation data
- All currency to USD rates over time
- Deal with missing data
- Use median of categorical data to replace missing values
- If missing data is too high (based on threshold), simply delete record
- Finally, send Pushover notification on successful ingestion of new films. We always want to know when new data comes!


")