
For people who care what they watch.
Here’s a practical, behind-the-scenes look at everything I’ve added to FilmFan over the last six months—across the app experience, data pipeline, ML features, and cloud/dev-ops. It’s been a busy stretch: faster UI, smarter reviews, sturdier data, leaner infrastructure, and a sharper model…
What FilmFan is: a personalised film-recommender where each user gets their own model. You typically review ~50–100 films (or as many as you like), and a machine learning job re-trains/refines your recs (in < 15 minutes). This isn’t a generic “top charts” feed—it’s tuned to you.
Also see past posts
• Previous “under the hood” summary
• Product summary
What’s new (Product / UI)
Review Films — “Smart Sort”
The review queue is now smart-sorted to keep the flow fast and most impactful. It blends:
- Easy wins you’ll likely recognise (newer titles and widely-rated crowd pleasers) so you can move quickly (and discover more).
- Your recommended picks that add the most learning signal.
Result: less clicking, more signal, better recs sooner.
Feels faster (and is)
I reduced unnecessary server round-trips and made the client snappier:
- Local pagination, lightweight logging, and UI updates.
- More polish across auth and UX (email login, Google/Facebook sign-in), cleaner navigation, and better tab-to-tab responsiveness.
Net effect: browsing, searching, and reviewing are noticeably quicker and more pleasant.
Recommendations — fresh in less than 15 minutes
After you review, a background job refreshes your recommendations every 15 minutes, so the list adapts to your latest input.
Search
Cleaner and faster, with multi-facet queries:
- “What films have Anne Hathaway and Meryl Streep been in together?”
- “Which film did I see Laura Dern in recently?” (Answer: Marriage Story.)
My Reviews
A dedicated space to: see, filter, search and tweak your past reviews. Also ideal for quick corrections if you mis-remembered a film.
Fun question: Have you seen more “Awesome” films than me?
Friends
Lightweight friends features let you peek at overlaps so that starting your movie night is painless—without an otherwise “let’s find a movie” time-sink.
Save Films
Save = “I’m curious.” Saves are distinct from positive ratings; it means you’re going to check it out and maybe watch it. It’s important to save because recommendations can be constantly updating, so it’s handy to keep track.
Data
Film-Universe enhancement
Defining which titles belong in FilmFan’s “universe” matters for both UX and model quality. Key lessons:
- Target audience is English-speaking users, so language and region rules matter.
- Foreign films absolutely belong—when they clear a quality bar (e.g., Parasite).
- Older films can be noisy or detached unless they’re well-established (e.g., Vertigo).
- Poorly rated films aren’t always poor training signals (e.g., Spread)—context matters.
These learnings turned into enhanced inclusion rules (vote counts by source, minimum rating by cohort, language/country normalization), enforced in the caching + processing pipeline.
Providers
- TMDb and OMDb are now first-class, with IMDb-derived metadata in the warehouse.
- Source quality varies per field; I added selection rules to pick the best value per attribute across all providers.
- Oscars data is now ingested to enrich awards-related features.
- Better schema normalisation across titles/years/genres/country/language codes.
Cleaning & consistency
- Hardened parsing for genres, runtimes, multi-country/multi-language productions.
- Languages/countries normalised (they drive both universe filters and ML features).
- Genres clustered to a stable main-genre set to reduce sparsity and noise.
Caching & re-caching
- Re-cache policy tuned by staleness + change likelihood (popular/new titles refresh more often than deep back-catalogue).
- Daily backfills to refresh fast-changing signals e.g. ratings for new releases.
- Titles can enter the universe later as their data improves.
Machine Learning
Pruned “bad” features
- Removed/down-weighted brittle signals (e.g., prompts that leaked era/genre or popularity proxies rather than taste).
- Converted some fields into binary presence features when “exists vs. not-exists” mattered more than the raw value.
- Fixed data-type edge-cases that introduced noise.
- Sometimes it’s not the feature that’s important but how often it has been in “Good” or “Awesome” films (e.g. Directors/Actors etc). Hence weighted counting features were introduced.
- Added training & testing harness to evaluate feature changes on real production data before going live.
Gen-AI features (vibe signals)
- Added prompt pipeline to label “vibes” e.g. films could have: psychological depth, hidden truths, shifting perceptions, realism vs. speculative, modern_realistic_setting, narrative cohesion vs. complexity, etc.
- These on cost-effective models (e.g., GPT-4o-mini / Claude variants) with guardrails.
- Outputs stored with rich metadata for reproducibility and analysis.
Model notes
- Still using XGBoost (One-vs-Rest) classifier with feature-importance checks and periodic audits.
- The combination of classic film metadata (director/cast/country/year/ratings etc) + stable vibe features generalises well across decades and genres.
Cloud / DevOps
Python upgrade
Standardised on Python 3.11 across app and jobs in Google Cloud.
Artifact Registry + one-command deploy
- Containers live in Google Artifact Registry.
- Single build-and-deploy scripts that creates docker images, pushes, and rolls out to App Engine / Cloud Run.
Leaner, lower-cost runtime
- App Engine F1 with a warm instance for predictable latency.
- Backend jobs on Cloud Run, scheduled via Cloud Scheduler.
- More proactive caching and re-caching to keep the data fresh fast.
- Cost drop from F4 instance and increasing responsive.
Mobile polish (ongoing)
- Small-screen ergonomics enhancements for reviewing/search; touch-target and keyboard-nav tweaks.
- Testing and refinement on iOS for new UI pieces.
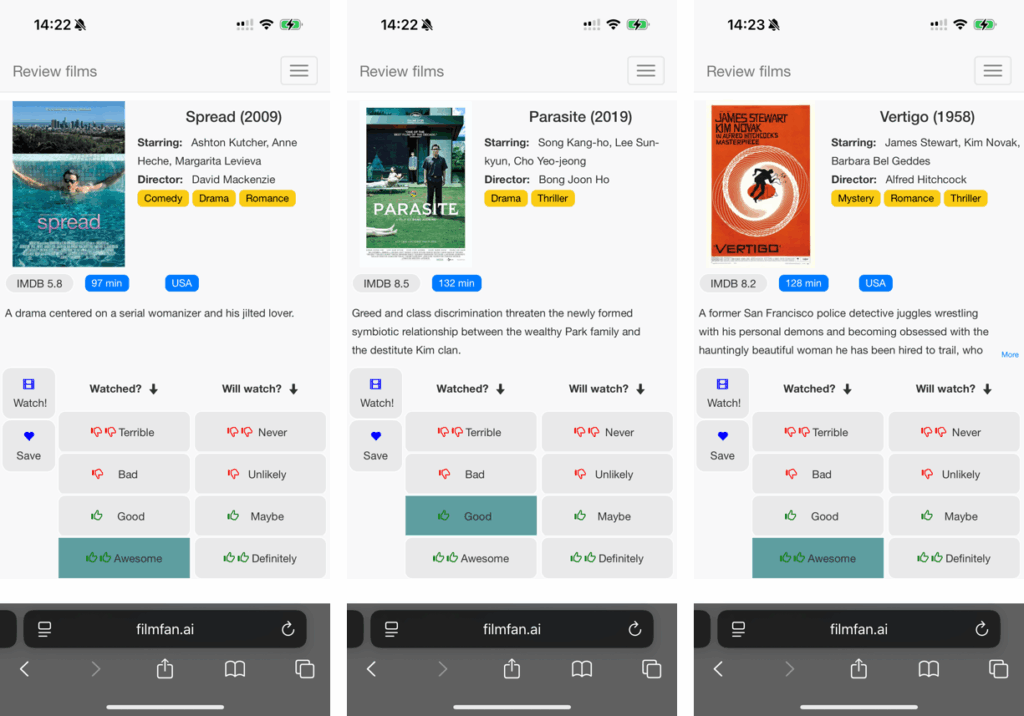
The experience today
- Review ~50–100 films (the smart sort keeps it quick).
- Wait < 15 minutes for the recommendations to refresh.
- See fresh recs that reflect you!
- Nudge the model (re-rate, save, skip) to keep learning.
No generic feed. No infinite-scroll anxiety. Just films you’re likely to love, surfaced faster.
What’s next
- Explainability you can trust: “Why this film?” tied to feature importances.
- Sharing with friends: don’t just share recs, share all films you’ve reviewed with low friction.
- More mobile fit-and-finish.
If you’ve tried FilmFan recently—thank you! If not, kick the tyres at https://filmfan.ai and tell me what feels great vs. what still feels rough. I’m building this for people who really care what they watch 🙂


")