
Prologue: Film Fan is your very own personalised film recommendation engine. Please check it out here: filmfan.ai. A full walkthrough of the site’s features and inspiration is covered in a previous post: here. This is a 5 part series to break down how I designed and built Film Fan, from all angles: data, engineering, analysis, machine learning, speed, productionisation, cost etc. For reference, please also see the previous posts in this series:
- Film Fan – Under the hood – Overview
- Film Fan – Under the hood – Data
- Film Fan – Under the hood – Data Collection
- Film Fan – Under the hood – Machine Learning
This final post summarises the previous 4 posts in the context of productionisation – which put simply is “How do we create a system of components that will have an enduring benefit?”. In other words, how can we make a system that is reliable, maintainable and cost effective in the long term. It’s not just a few principles but many components coming together for the most productionised solution. These components for Film Fan are built around Google Cloud plus a few internal and external tools and outlined below.
Google Cloud Run
Google Cloud Run (GCR) is used as the backbone of Film Fan’s data engineering because of the wide and varied nature of sources and destinations required to be processed, including:
- Flat CSV files (from offsite server)
- API based film attributes (captured per record)
- SQL Database (BigQuery)
- NoSQL Database (Firebase)
- Cloud Storage for cache (Google Cloud Storage)
These data sources and destinations are used across the 3 distinct data and machine learning (ML) engineering processes. Each job is designed to take no longer than 15 minutes to run and the ML job much quicker since it runs every 30 mins on receipt of new data collected (See more details for these jobs in overview). In order to coordinate these sources and destinations GCR acts like a virtual server except it’s completely serverless since it runs from ephemeral containers established with docker files.
The docker files are built dependent on the needs of each data and ML engineering job, and will install the necessary dependencies based on what is required. In addition to the Python libraries, I also installed the two internal python packages to ensure the data transformations needed on both the front and the back end were consistent. Here is a high level layout of the docker steps required for each container (one per data engineering job):
- Use Python slim base– basic linux installation to run Python.
- Run command to ensure logs appear in Google Cloud Logging (as standard input/output).
- Set credentials configuration for Google Cloud – To authenticate to cloud services.
- Install non Python dependencies (e.g. gcloud SDK)
- Set path dependencies – to ensure installations work.
- Download internal packages (used for front-end and back-end data transformations)
- Previously built and deployed to GCS as Python packages (using setup.py)
- Downloaded from GCS (versioned)
- Install all Python requirements
- Run gunicorn (web server) to enable the job to be triggered.
- Job is triggered by a HTTP Request from Google Cloud Scheduler

Google App Engine
Google App Engine (GAE) serves as the backbone for the website of Film Fan. When you load filmfan.ai, a request is sent to GAE web server to send the webpage: HTML/Javascript which is rendered/executed on the client side. Due to the heavy usage of Python/Pandas for bespoke data transformations for the list builds, the server requests can sometimes take time, so they were sped up with caching as defined here. Otherwise the core of the app is data collection which uses vue.js javascript code running on the client side with low latency reads and writes to Firebase (see details here).
GAE like GCR comes out-of-the box with not only logging and monitoring, but automating scaling and deployment options. It merely needs a configuration of how heavy you need the ephemeral servers (aka instances) to be and how many instances need to be live at any point in time. Adding more instances (i.e. horizontal scaling) is preferred when there are many concurrent users, whereas increasing the size of the instance (i.e. vertical scaling) can only be done on deployment. It required a bit of trial and error to see how much memory and compute the instances needed to be.

Coding, logging and monitoring
The main productionisation benefit of GAE and GCS is that they are well supported out-of-the box with monitoring and logging solutions from standard output. You still need to send meaningful logs to the application and data engineering jobs; but that’s just the nature of good quality programming. Which also requires you to ensure the code is clean, well packaged and maintainable, which I speak about here, so that logging then merely becomes an entry point to the code when it comes time to debug or optimise issues as they arise. With clean packaged code, then we write tests for each module end-to-end.
Within Google Cloud Logging, we can filter by App Engine or Cloud Run(and the job being used) See screenshot example below to time-based logs for “users and recommendations pipeline”:

Alerting and cost control
I’ve opted for an alerting solution outside of Google since I wanted the flexibility to have simple pushover notifications sent to my phone and watch to fully stay on top of everything happening in the app – good or bad. When the data and ML engineering jobs finish I get these notifications. See examples below:
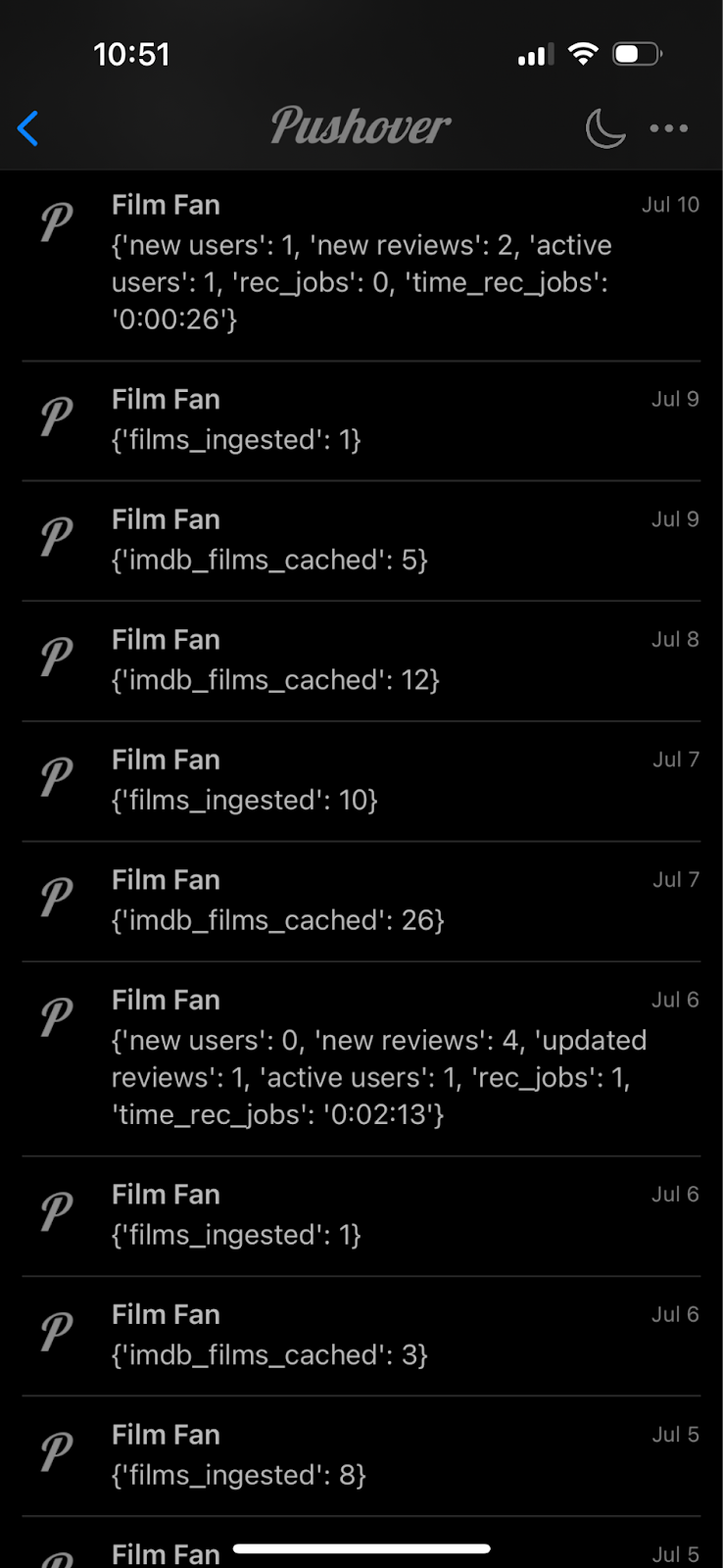
When a scheduled job doesn’t send me a notification I know it could perhaps have failed silently. It’s also great to see the notifications every day when a new user signs up, or performs film reviewing on the app, or just merely logs in. This helps to understand the engagement within the app also.
Another tool used for alerting is UptimeRobot which lets me know that the website server is running. It also acts as a “keep-alive” script in times when I need the app to remain live during heavy traffic times (to prevent GAE servers from shutting down to save cost). This keeps a good balance of cost vs reliability vs latency. Although similar tools like this exist within Google Cloud itself, it makes sense to have it external since it can also quickly tell me if there is an outage in Google Cloud itself.

")
