
Prologue: Film Fan is your very own personalised film recommendation engine. Please check it out here: filmfan.ai. A full walkthrough of the site’s features and inspiration is covered in a previous post: here. This is a 5 part series to break down how I designed and built Film Fan, from all angles: data, engineering, analysis, machine learning, speed, productionisation, cost etc. For reference, please also see the previous posts in this series:
This is a post dedicated to arguably the most important aspect for any data project – collecting data. We unpack why this is so important, how it was approached, what we must overcome to optimise the process, along with the results and ongoing challenges.
Data collection is a top priority
As discussed within overview, Film Fan at its core is a data collection machine with AI recommendations as an output. Throughout my career as a data specialist and while building Data Karate, finding and collecting valuable data has been a consistent focus. This notion is best described within a very influential book “Big Data – A Revolution…” which discusses the idea that data is valuable and extracting the value becomes the commodity in the future, hence focus on collecting your data. But not just collecting any data, collecting data intentionally and strategically that is valuable.
For Film Fan, if we start with a problem and work backwards we can clearly see why this is so important:
- “I can’t easily find any inspiring/moving/high-quality or ‘life-altering’ films!”
- We could use AI to find these films.
- The AI would need state of the art Machine Learning systems.
- Once the state-of-the-art ML system is established, further optimisations would need to happen from better/more data.
- We don’t have enough data or high enough quality data.
- We need to collect more data.
- We need to collect it in the best way to get the most high quality data possible.
Hence, the data is the value (the gold) so we look after it as such, collecting it with care and focus.
How it works
As discussed in Data Collection of “part 2 – data” of this series, the data collection is designed to be as simple as possible, with all information at your fingertips and merely a single button press required for each review (as depicted below):

Under the hood however, to achieve this, a number of tools were connected together to enable:
- Fast collection of data
- Reliable collection of current and historical data
- Collecting meaningful data (based on ordering).
See system architecture again below, with the app in the bottom right corner.
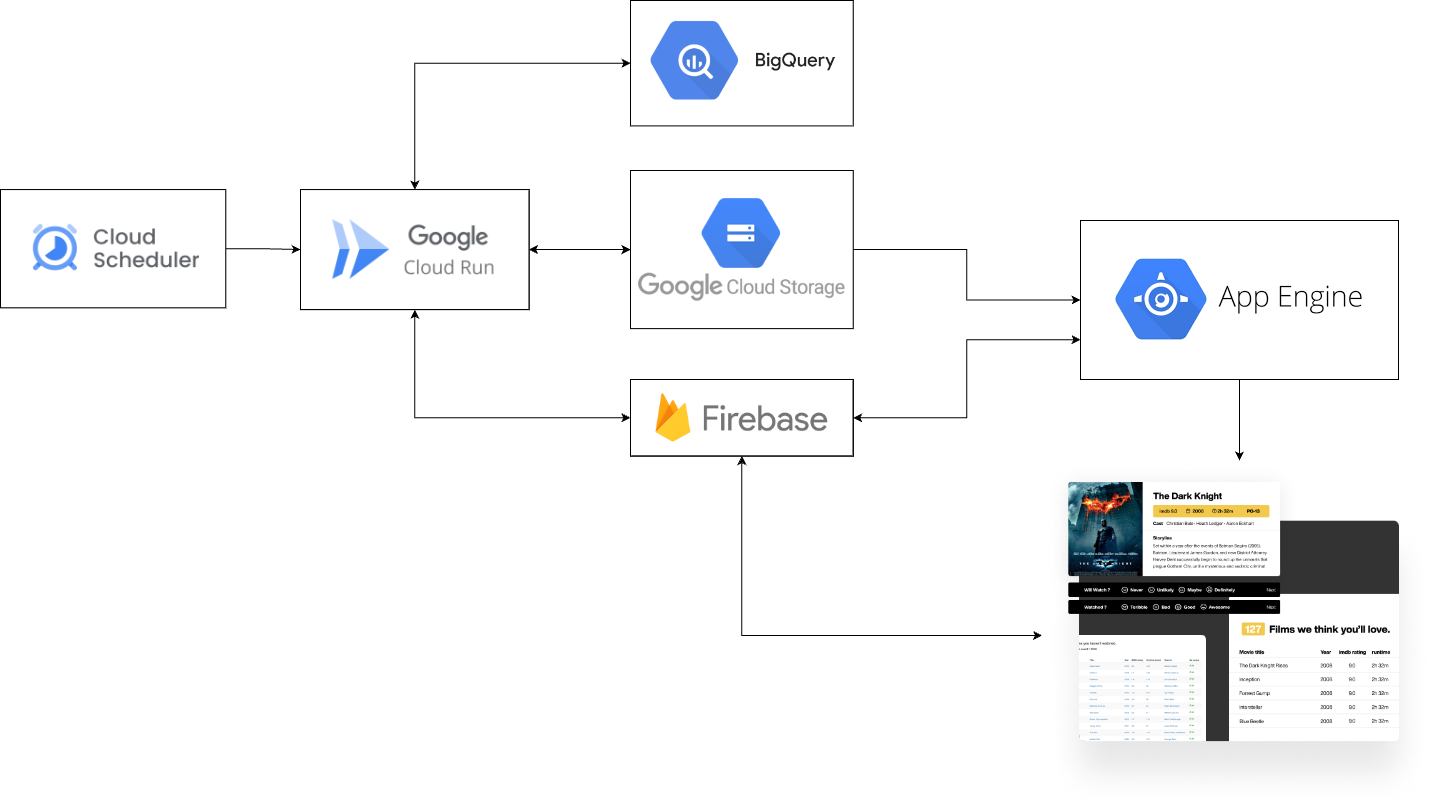
The way this works from the data collection point of view is:
- User logs into filmfan.ai
- Immediately is redirected to film review page
- App Engine serves webpage (HTML, javascript code)
- HTML – page elements
- HTML – list of films to review (pre-ordered)
- Javascript – Vue.js application
- Javascript runs the data collection app, loads new film on each button press
Making it fast
There are two sides to making the data collection fast:
- Loading the webpage – for more details see section App Caching in this post.
- Loading the next film to review – this is the Vue.js application outlined below.
Critically, to capture many data points in quick succession, we need to ensure there are no web server requests in between each button press. This means that data flows directly to and from Firebase from the client (the users’ front-end). Since javascript is the de facto language for running applications on the client side, we need a javascript framework. For simplicity, Vue.js was chosen as the most lightweight option available. Other javascript frameworks seemed heavy handed for the task at hand and had unneeded features like – javascript back-end.

Here is the main flow of actions in the Vue.js application. All of which takes place without ever having to contact the web server!
- Read film details from Firebase films collection for ‘next film’.
- Load film cover-art from Google Cloud Storage (pre-cached in back-end job).
- If the back/forward button is pressed: load/previous next film in order.
- If review button is clicked, load next film in order, AND store review data in Firebase, in 3 Firebase collections:
- Reviews – the source of truth for all reviews as of now.
- Historical reviews – all reviews ever created.
- Current reviews – the reviews since the last caching (see App Caching above).
The result is fast! Data collection can happen in the background with asynchronous tasks sending/receiving data from Firebase.
Ordering data to optimise meaningful data collection
For the film universe of nearly 20k films in Film Fan, we not only need to collect as many data points as possible but data points that matter since these examples can serve as the point of difference for what the user likes and does not like – and hence how the AI can infer this from the data. To that end, we need to ensure the films reviewed are most likely worth the time for the user. For example if we were to send the user only films made in 1900 with a score 5/10, we know intuitively they’re unlikely to be films they’d want to see, so using this data we learn nothing. We need to show users films that are a good combination of:
- Higher IMDB rating
- Newer (more recently made)
To achieve this, we merely take for all films, the year and rating and calculate normalised values of these between 0 and 1 (i.e. percentiles), then take a weighted average of each year and rating percentile.
Take the following examples:
- Vertigo (1958) – rating: 8.3/10
- Poor Things (2023) – rating: 7.9/10
Both are great films, however Vertigo being one of the classics is a little bit old now, so in which order would these films be served? Let’s say ‘year weight’ is 80%, then normalised (order) scores would be:
- Vertigo: 80% x 1958/2024 + 20% x 8.3/10 = 0.9399
- Poor Things: 80% x 2023/2024 + 20% x 7.9/10 = 0.9572
Hence “Poor Things” is served before Vertigo. If however the ‘year weight’ was only 20% (i.e. we care more about rating than year), then the order would be reversed.
This ordering takes place in advance in one of the data engineering jobs (mentioned here), and is fully updated across all films for each job run, which ingests new data for new films almost daily (or whenever they become available to IMDB). The above provides a great mix of both new and highly rated films.
Challenges
In no particular order, here are some of the main challenges with data collection from a design and implementation point of view. Working on these challenges will serve as enhancements in future iterations.
- Vue.js is a javascript library which requires specialist skills – a seasoned web developer could add enhancements (since I’m a data specialist not web specialist).
- Budget – since cost is of the essence, various tools were essential to be used in conjunction. We could add more features and enhancements with much more expensive tools for caching data – e.g. Memcached or Spanner etc.
- Getting users to review enough films – this is more on the marketing of the tool, but also using feedback from data collection to see how it’s tracking. For example if a user only reviews 3 films, it’s likely no recommendations are available.
- Is there enough data displayed for a user to make a review? For example the plot summary is truncated if it’s too long since we wanted to avoid scrolling or differing sized page elements.
- Is the user being consistent with their review? Even myself having reviewed 12000 films realised that on some days my mood had differed and I was not being diligent or consistent enough with my scoring. The good thing though is one can change their review at any time and the historical data is captured to know how/why certain recommendations were given by the AI at any point in time.


")